

One algorithm to rule them all: Gradient Descent
One algorithm to rule them all: Gradient Descent
Warning: There will be maths

👋🏽 Welcome to Brick by Brick. If you’re enjoying this, please share my newsletter with someone you think will enjoy it too.👇🏽
Chances are high that you’ve heard about Machine Learning (ML). ML has seen substantial advances over the past decade and has already impacted our lives in many ways. Netflix movie recommendations; ML. Email spam filtering; ML. Alexa’s voice recognition; ML. But what exactly is ML and what sort of magic happens behind the scenes for these products and services to be able to perform human-like activities?
I won’t be going in depth in ML, that will require a lot more than this blog post. I will try and describe one very basic algorithm that is at the heart of many ML models - Gradient Descent. My intent in doing so is to give you some basic intuition into how ML works.
One distinction I would like to make is the difference between ML and traditional software. Machine learning doesn’t rely on hard-coded rules, which is how traditional software is developed. In traditional software applications, the code defines the logic that the software will follow. Machine learning relies on detecting patterns from lots of data. Machine learning builds a mathematical model that looks for patterns between the data you give it (training in ML parlance). The model will then be used to predict outcomes or values for data it hasn’t seen before. As a rule of thumb, the more data an ML model is trained with, the better the model.
Before diving into Gradient Descent, it is worth noting that the main concepts behind ML are decades old. The history of ML goes back to the 1940s (and earlier, depending if you include Bayesian statistics). I highly recommend navigating through this article to explore the history of ML and some of the more seminal events in its history.
I believe ML will continue to have a profound impact on our lives and knowing a little bit about how it works might be useful. My hope is that basic understanding of ML will help you understand what these models do, again at a very basic level.
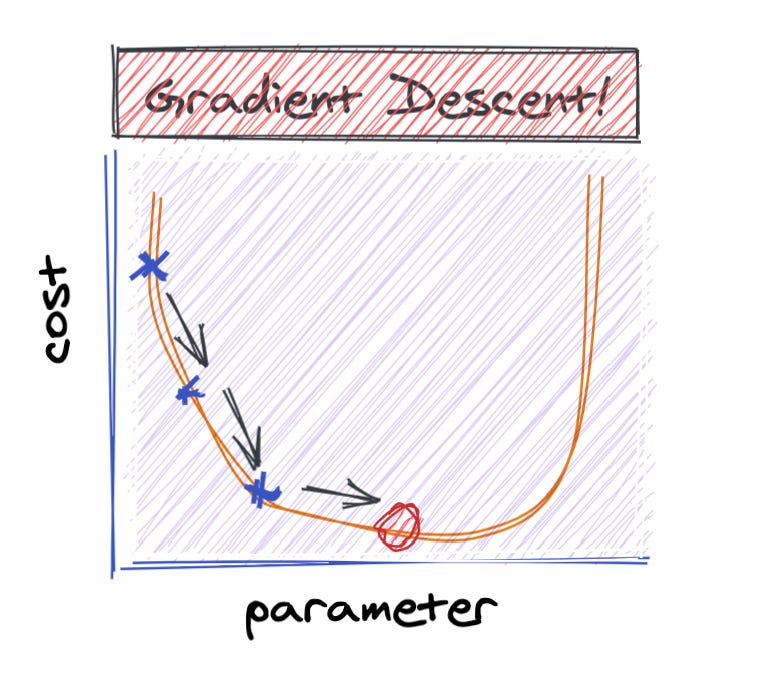
Gradient Descent
Wikipedia defines Gradient Descent like so:
Gradient descent is a first-order iterative optimization algorithm for finding a local minimum of a differentiable function. To find a local minimum of a function using gradient descent, we take steps proportional to the negative of the gradient (or approximate gradient) of the function at the current point. But if we instead take steps proportional to the positive of the gradient, we approach a local maximum of that function; the procedure is then known as gradient ascent. Source: Wikipedia
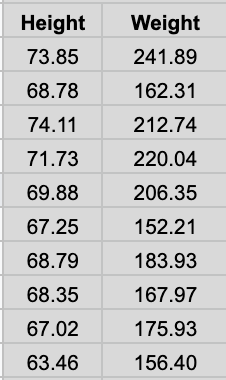
We’ll explore what that actually means by walking through a simple problem. We’ve been tasked to come up with an algorithm that can predict a person’s height given their weight. You’re also given a dataset that contains the weight ( in lbs) and height (in inches) of 5000 random males. Note that I’ll be saving off about 1000 randomly selected data points from the set I have to later on test my model (the test set in ML parlance). The remaining ~4000 data will be used to train my model. This is knows as he training set. A snippet of the data is shown below
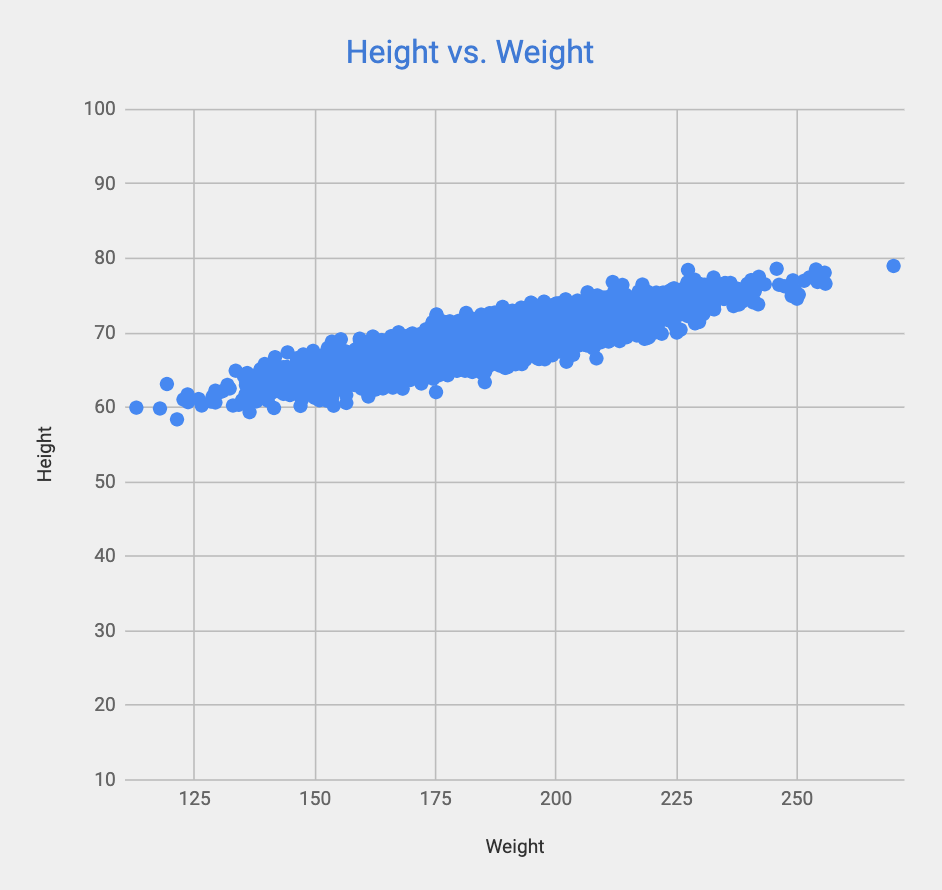
If you chart this data on a scatter-plot, you will notice that there is a linear relationship between both variables as shown in the chart below.
If you remember your high school maths, you might recall the equation for a line
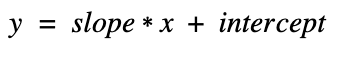
In our case, we can rewrite this equation as such:
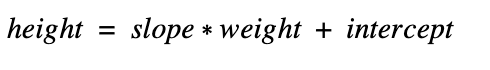
In order for us to be able to predict a person’s height given their weight, we will have to build a model that finds the values of the slope and intercept. If we know the slope and intercept, then we just plug in the weight and voilà we have the height.
Gradient Descent - The manual version
To make this a bit simpler (as well as a shorter post), I will cheat and set the slope to 0.125. Our job then is to find the value of the intercept. This is a short-cut done for the sake of brevity. In reality Gradient Descent can deduce both the slope and intercept and lots of other variables too.
To start off, let’s pick a random number for the intercept. I think 37.5 is a good start (yep, another shortcut). Our equation for the height and weight can now be expressed like so:
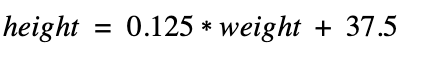
We can then use this equation to predict the heights of individuals given their weights. For example, for someone who weighs 241.8 lbs, our equation predicts that that person’s height is 67.7” and so forth. We can just plug in a value for the weight and get the height. Easy.
Remember that we have the ~4000 data points in our training set. We can use this data to test our equation. It turns out that from our training data one of the males (there’s only one) that weighs 241.8 lbs is actually 73.8” tall. Our prediction was off by 7”. We repeat this process for the entire training set. At every time we calculate a predicted value based on the equation above and compare that with the actual height. The difference between the predicted value and the actual value is called the cost. Technically it’s called the residual and it isn’t really just the difference between the actual and predicted value - it’s the square of that.
The table below shows the results of using this equation to predict the heights of the first 10 data points. We will do this prediction for all the training data that we have, calculating the prediction and cost at every data point. We then sum up cost across all the data points. Our goal is to find an intercept that minimizes this cost across all the training data points that we have.

We will repeat this process for different intercepts. Recall that we started at 37.5, we then bump that to 40, then 42.5, 45, 47.5 and so on. I basically incrementally increased the intercept by 2.5 for every iteration of this process. I could have also decremented the intercept. Again, short-cut.
If we keep on doing this repeatedly we can then plot the total cost we calculated at each intercept, which is shown below. We can visually see from the chart below that the lowest cost is somewhere where the intercept is around 45, but where exactly?

Clearly this is manual, repetitive but it has some promising results as we’ve shown. We’ve started from a guess and iteratively found the area where our equation would yield the best results. We can do better. Enter Gradient Descent.
Gradient Descent - The Algorithm
Let’s assume that we have the following data point (height=73.85, weight=241.89). Using the equation we derived earlier and fixing the intercept at 37.5 we can calculate the cost like so:
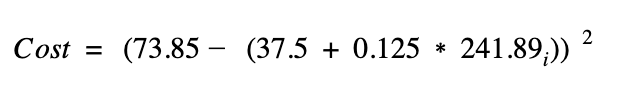
or generally speaking like so:
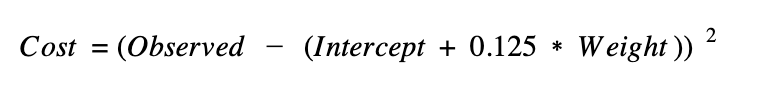
In reality we have more than one data point, so the equation for the cost function is

Where i ranges from 1 to the number of training data points we have (~4000)
With this function we can then calculate the derivative of the cost with respect to the intercept. “Derivative of the Cost with respect to the intercept” is a fancy way of measuring the slope of the cost function at a certain value for the intercept. Graphically it would look like so:
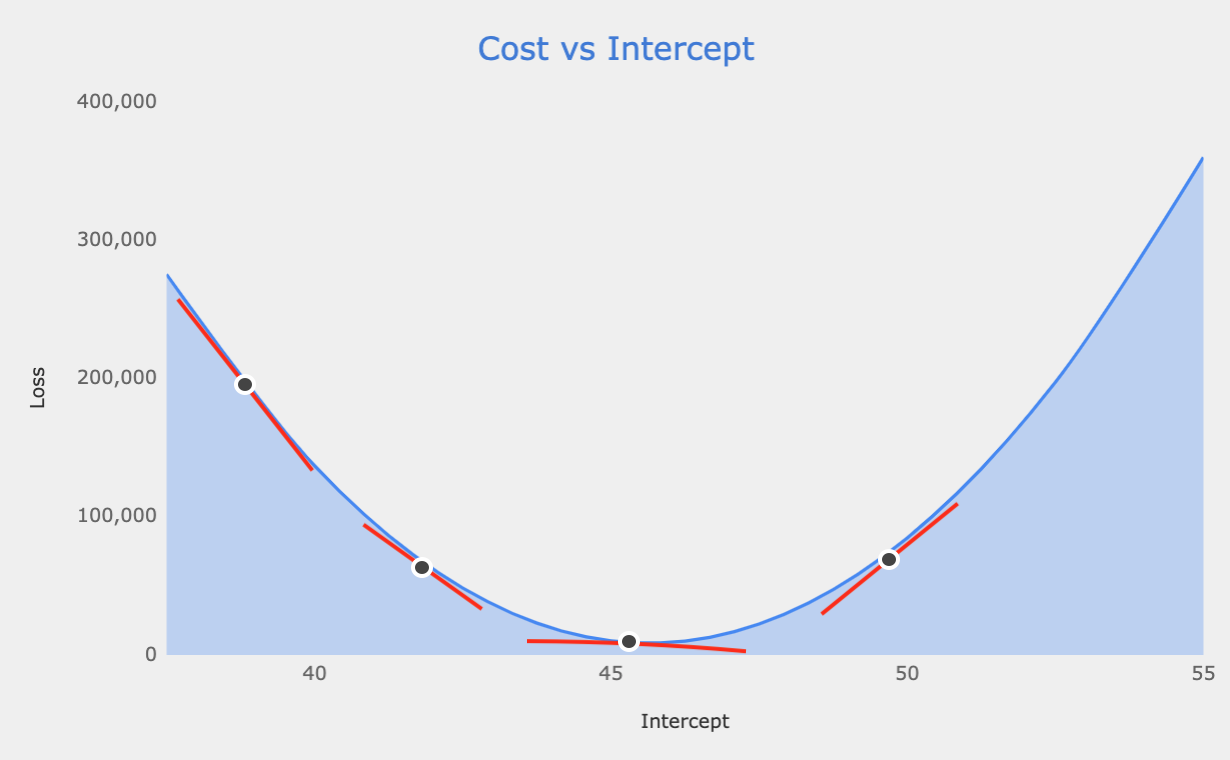
These red lines are the slope of the cost function at a certain value for the intercept - they are the derivative of cost with respect to the intercept. One final point about slopes. If the line is sloping downwards from the left to the right, then the slope is negative. Conversely if the line is sloping upwards from the left to the right, then the slope is positive.

What we are trying to do is find the point at which the slope of this line is as close to 0 as possible. Let’s say we started at an intercept value of 37.5, we know from the graph above that the slope of the cost function when the intercept is 37.5 is negative. What we want to do is move downwards on this cost curve towards the point where the intercept is closest to 0. To do so, we adjust the intercept we used (37.5) to some new value which is based off the slope we observed.

Technically this isn’t totally accurate. We adjust this by a term called the learning rate, which I omitted for simplicity. Because the slope in our case is negative, the new intercept will be larger than 37.5. We’re descending along the curve.
Wow, we’ve just moved to closer to an intercept value of ~45, which is where we expect the most optimum intercept to me. Gradient Descent will continue to adjust the intercept based off the slope (derivative) at each iteration of this algorithm. The initial steps might be big jumps, meaning the difference between the new and older intercept might be large, but will quickly get smaller and smaller especially as it converges to the point where the slope is closest to 0.
A good analogy is if you toss a marble in a bowl. The marble will start off by rapidly moving back and forth along the inner walls of the bowl, but will soon settle to slower oscillating motions. Ultimately, it will settle at the lowest point in the bowl. And that in a nutshell is what Gradient Descent does. It tries to optimize a function by taking incremental steps along that function’s curve.
For those curious to know the actual answer for the height/weight equation, I ran 100 iterations of Gradient Descent using this dataset on my laptop and it came back after a few seconds with the following equation.
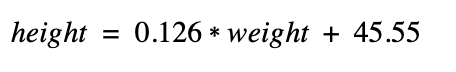
I tried this equation on the ~1000 test samples I had and it was ~98% accurate. Not bad.
So there you are, that’s Gradient Descent in a few pages. Gradient Descent is actually a big deal. Here’s what Andrej Karpathy - Director of artificial intelligence and Autopilot Vision at Tesla - had to say about it:

Source: Twitter
I hope this gives you some very basic intuition about one of the most popular algorithms used in ML.
At their heart ML models are optimizations typically based on billions of computations and massive amounts of data, making them incredibly suitable for computers to process and one of the reasons they are very popular nowadays.
Thanks for reading! If you’ve enjoyed this article, please subscribe to my newsletter👇🏽. I try to publish one article every week.