

Software 2.0 vs Software 1.0


I recently joined a series-A startup - Kheiron Medical - that is a pure-play machine learning (ML) company. Kheiron develops AI-based products that are used by radiologists to detect breast cancer in women.
One of my motivations for making this move was to gain a better understanding and learn about ML companies and how they differ from traditional software development, which is my background. In this post, I will cover the differences between traditional software development and ML from a developers perspective. I will also cover the implications of these differences on the economics of ML companies and the interaction of ML and humans in follow-up articles.
Throughout this article, I will be comparing and contrasting between ML and traditional software development. I will be using the terms Software 2.0 to refer to ML and Software 1.0 when referring to traditional software development. These terms were coined by Andrej Karpathy in this talk.
Software 2.0 vs Software 1.0
Software 1.0, is primarily concerned with writing code that governs the behavior of the software. This code, written by programmers, represents explicit instructions that the program will execute. Once developed, software is used to make some computations based on some input to it. The computation maps the input data onto the written code. The example below illustrates the result of inputting a value 5 onto a very simple code sample, which does nothing but return 1 added to input value; 5 + 1 = 6.
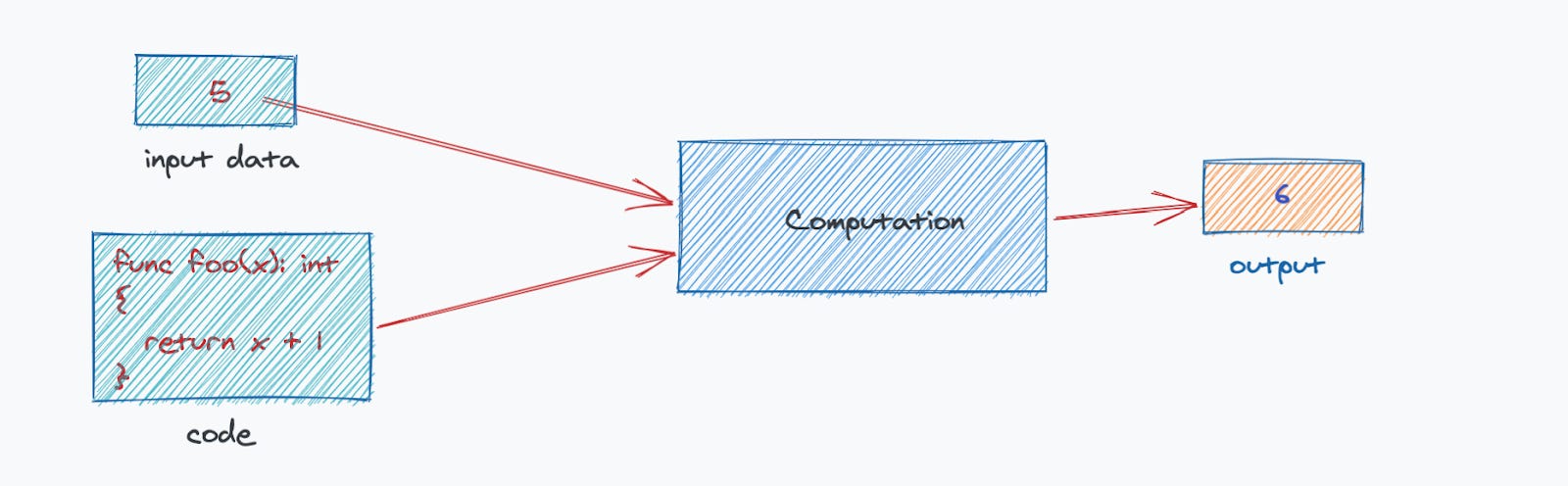
Software 2.0 is fundamentally different from Software 1.0 in that there is no code that a programmer writes. In fact, the “code” is discovered from computations. An analogy might help explain how Software 2.0 works.
Suppose that you wanted to teach a child how to recognize different geometric shapes; circles, rectangles, squares and the like. You could train your child to recognize these shapes by using flash cards. You would show your child a flash card and tell her what shape is drawn on the card. For example, if the card had a circle you would say “circle” and so on. Over time, you would ask your child to recognize the shapes shown on cards and would correct her if she misidentified them. With more practice your child will eventually learn to recognize these shapes.
Software 2.0 is no different than teaching a child. What ML attempts to do is to find patterns, or optimizations, given some input data and a target output - the equivalent of flash cards with shapes drawn on them. When building an ML model, we need well labeled input data, a model architecture (beyond the scope of this article) and a desired result for each input data. We then rely on computations that run the input data over the model’s architecture. That is referred to as training an ML model. With sufficient training, we can produce the equivalent of the “code” of an ML model. The code in this case being the weights of the model.

Consider the simple neural network shown below. It is composed of 3 layers, an input, hidden and output layer. The input layer is in turn composed of two input nodes X1 and X2. The input nodes are fully interconnected with the two neurons of the hidden layer N1 and N2. The interconnections are via the weights w1, w2, w3 and w4. Each hidden layer neuron applies a mathematical function on the input nodes connected to its associated weights. This same process applies to the connections between the hidden layer neurons and the output layer’s single neuron N3.

In the example above, the network can be represented via this mathematical function, which returns a value between 0 and 1. The purpose of training a model is to find the optimum weights of the network, in our case these are w1, w2, w3, w4, w5 and w6

Once a model has been trained, you can use it to reason over data that it hasn't seen before, and make predictions about this data. For example, one can train a model to recognize pictures of cats, given a sufficiently large and diverse dataset of cat pictures. Once that model has been trained it can then be used as a cat recognition iPhone app. You might want to read this article for a very quick overview of training and weight derivation.
With that, we are now ready to dive into the implications of ML and how those are fundamentally different than traditional software development.
Data
It should come as no surprise that one of the main differences between both paradigms is data. Software 2.0 requires data, the more of it and more diverse the better. Data is so critical to Software 2.0, that it typically consumes most of what an ML team does. In fact ML code represents a very small fraction of ML systems. The vast majority of the code in ML systems are for the surrounding infrastructure (mostly data) to help build and serve ML models, as illustrated in the below diagram.
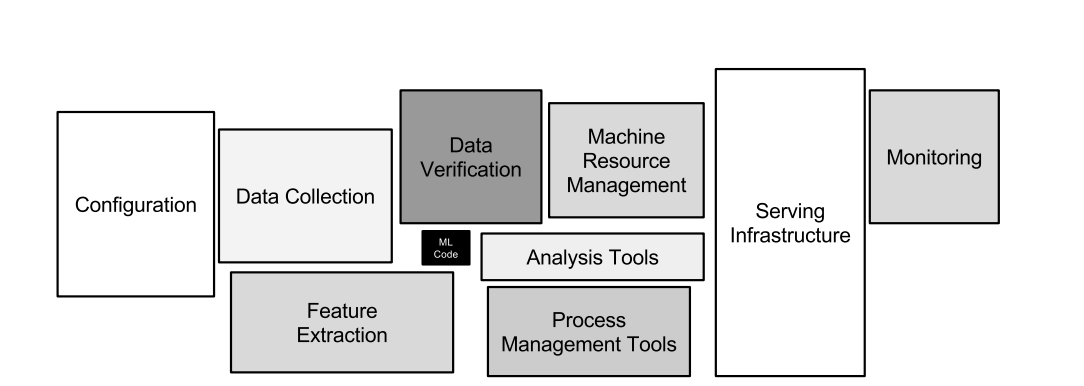
Source: Hidden Technical Debt in Machine Learning Systems
An example might illustrate the importance and complexities of data.
Let’s imagine that we were tasked by an auto manufacturer to build a model that can recognize cars. Our model will be part of the manufacturer’s autonomous driving vehicle module. The first problem we will face is sourcing this data we need to train our model with. We could try and scrape images of cars available on the internet. We could also supplement our dataset by purchasing car image datasets. We could also pay people to take pictures of cars on their phone and send those to us. Getting data is hard and it is the crux of what an ML company does.
Next, we will have to ensure that the dataset we have is correctly labelled. This simply means that the area of the image representing a car is correctly identified. If we feed our model images of cows and label those as cars, well our model will learn to recognize cows as cars. Labelling is mostly a manual task, further highlighting the complexities and difficulty of getting data.
This problem is also much more nuanced than trying to correctly label the objects to recognize. For example, are the pictures below of cars, if so where are the boundaries of these cars in each image? Remember, our model will be used in real life to detect other cars on the road - it better recognize anything that resembles a car or moving object!

As a general rule of thumb, ML models should be viewed as dynamic and evolving, versus being stale. You should strive for ML models that can generalize and continue to perform well against new data. Generalizability is the robustness of your model in dealing with a very wide variety of data once it is trained i.e. can our model recognize all cars. Generalizability requires that you continuously feed and train your model with new data, especially data from distributions different from ones it has been previously trained on.
There are profound implications to this.
The first is Software 2.0 companies will continuously be looking for new and varied data to train their models on. That is an expensive endeavor, as we will discover in future articles. The second, is ensuring that models once deployed will adequately perform and to be able to react when they cannot generalize against new data. Both of these will impact the profitability and operating structure of Software 2.0 companies. We will revisit this in subsequent articles.
Development Environment
Decades of investments in software development have resulted in a rich ecosystem of tools for Software 1.0 engineers. Integrated development environments (IDE) are plentiful and ever so powerful, so are source control systems like GitHub and continuous integration and continuous deployment tools like Gitlab, Jenkins and others. So are other tools like debuggers, profilers, tracing, monitoring and more. That’s not the case for Software 2.0. Not only is the tooling still somewhat primitive, it is also extremely fragmented as illustrated in the diagram below.
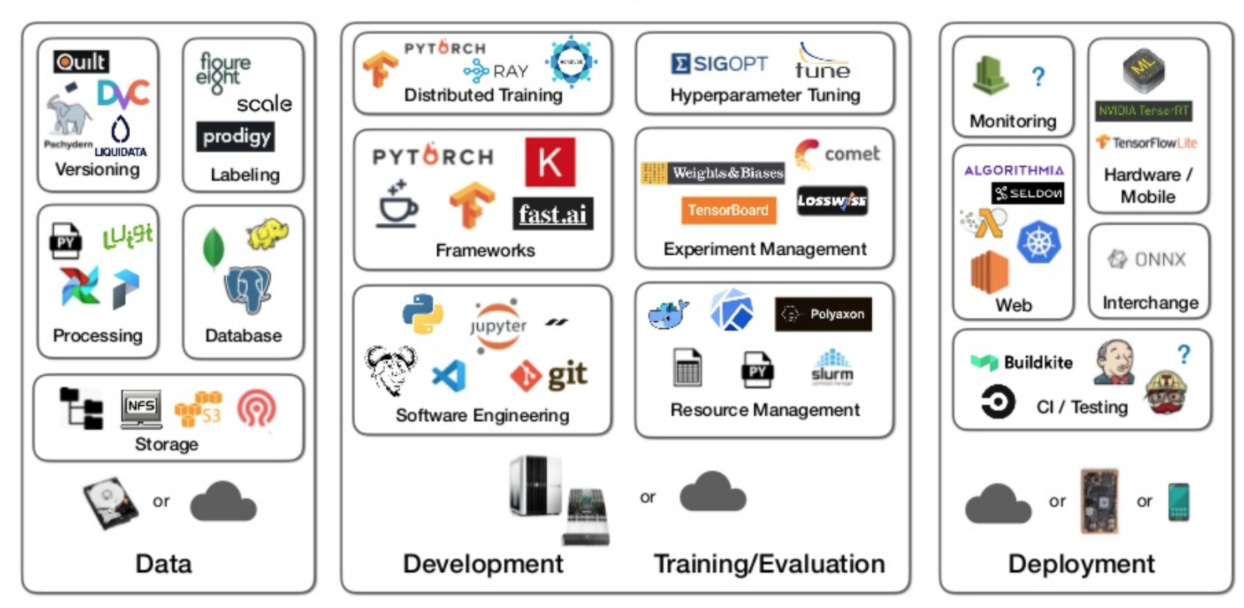
Source: Sergey Kareyev at Full Stack Deep Learning Bootcamp November 2019
Moreover, some of the tooling that Software 2.0 requires has simply no equivalent in Software 1.0. I had mentioned earlier that data in Software 2.0 is akin to code in Software 1.0. In Software 1.0, we can version control code with tools like GitHub, but alas one can’t do that easily with data. You simply cannot version control millions/billions of images with the existing SVC systems that exist for Software 1.0.
It is fair to say that it is still very early days for the Software 2.0 stack and tool chain, both of which are still under development. In fact this area, in particular MLOPs, is witnessing growing interest both from the OSS and startup community like DataRobot and Algorithmia to name a few.
Testing
As I mentioned earlier, ML systems differ from their software brethren in that they are not specified in code. The closest to code in ML systems is data, which makes testing ML systems quite challenging. Moreover, building ML models is an iterative and experimental process. ML engineers will experiment with many model architectures and datasets until they settle on a model that meets some requirements and criteria. The development of ML models is non-deterministic due to relying on stochastic parameters during model training making it challenging to go back in time and reproduce models. All of these factors make testing Software 2.0 products more complex than Software 1.0 ones.
Some of the challenges are in testing data, model versioning, which is a function of model architecture, stochastic parameters and training data, model validation and reproducibility. Another challenge is the lack of tooling: there isn’t a readily available CI/CD pipeline for ML systems. Monitoring and observing deployed models is also challenging. For a good read on this topic and some suggested solutions, I strongly recommend Martin Fowler’s article
Run-time properties
Trained ML models have some very interesting properties. Recall, that an ML model is nothing but a computation over some input data. Conceptually speaking, trained ML models are similar to maths functions, albeit a lot more complex. For example, the function f(x)=log(x) has the following properties. These same properties also apply to the equation I gave earlier for my neural network example.
First, it’s output for a given input is deterministic. No matter how many times we compute log(10) the result will always be 1. Traditional software doesn’t behave like that. Traditional software has conditions (if-then-else) and parallelism (threading) that can make it behave in a non-deterministic manner (e.g. race conditions).
Second, the resources that the log(x) function, both in terms of compute time and memory will not change. Again, software systems do not behave this way. Their run-time and resource usage can vary. This final property enables ML models to potentially be executed in hardware (ASICs), which can dramatically accelerate their execution speed. A good example of this are Google’s TPUs which are hardware accelerators specifically designed for Google’s TensorFlow ML library.
Final thoughts
I hope this sheds some light on the main differences between building ML systems and traditional software ones. I used the terms Software 2.0 and Software 1.0 to describe these two different paradigms, but I do not believe that one will supersede the other. There will always be domains that traditional software is best suited for as there will be for ML. It is worth noting, that ML systems require a significant infrastructure investment, which is the realm of Software 1.0. In time, I expect that the balance will shift to more development done in the Software 2.0 paradigm.